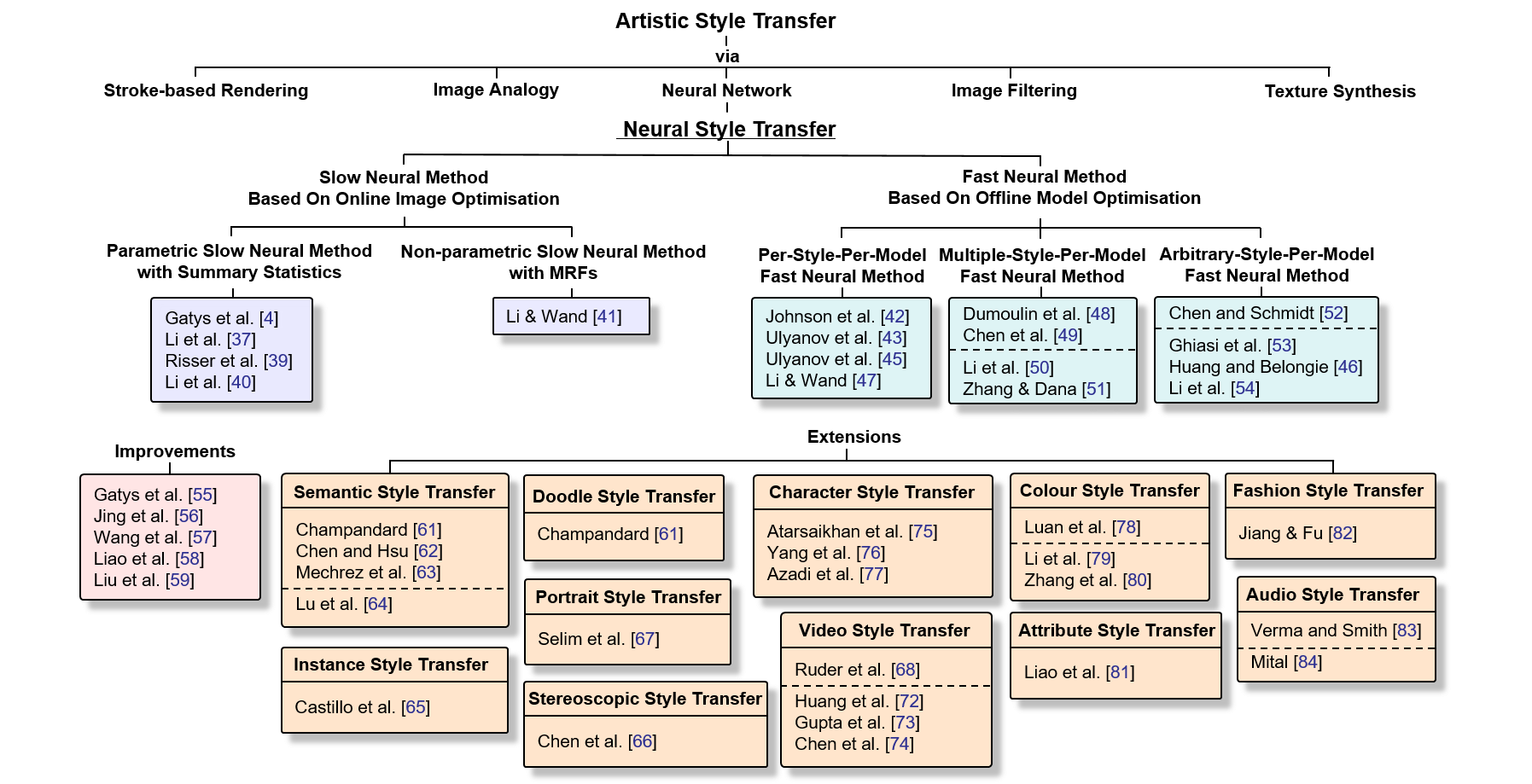
1. What’s Neural Style Transfer?
大家對 Style Transfer 這個詞可能很陌生,但應該很多人記得 2016 年在 Apple Store 和 Google Play 兩大平台皆奪下年度 App 的Prisma ,將照片轉換成畫作的功能大受歡迎,或者你也可能記得或甚至使用過Facebook 開發的 real-time 藝術畫風濾鏡 。

Neural Transfer 就是這種將畫作上的藝術風格移植到其他圖片上的技巧,而這周要介紹的論文實作便是這項技術的開山之作《A Neural Algorithm of Artistic Style 》(2015 年發布於 arXiv,2016 年發表於CVPR 上),作者為來自德國 University of Tübingen 的計算神經科學學者Leon A. Gatys , Alexander S. Ecker, Matthias Bethge ,他們嘗試用 CNN 來實現這一項過去被認為是專屬於人類的技能並獲得廣大迴響,三人也憑此技術創立一家公司 。
2. How it works?
TL;DR: 使用一個 pretrained CNN model,輸入內容圖(C)、風格圖(S)、輸出圖(G)三個圖片(其中輸出圖初始化為 white noise 或 noisy 內容圖),選定 model 中要使用哪幾層,再以三張圖在這幾層中的 activation 值設計出 cost function,最後 backprop 更新輸出圖(G)上的 pixel 值。
2.0 Rewind: What does CNN captured?
首先,我們要回憶一下 CNN 架構實際上做了哪些事情,2013 年 ImageNet 冠軍ZFNet 論文 (也是 PyTorch Taipei 第二周主題,可以參考士永社長提供之講解資料 與影片 )中提到,他們嘗試將每層中 activation 值最大的部分,還原出是在原圖上的哪個區塊,並發現較為淺層的捲積層捕捉到的只是單純的線條與顏色,然而越深層的捲積層捕捉到的會越趨一個完整的物件。而本篇論文就是利用 CNN 架構能捕捉不同規模之特徵的特性,嘗試將不同的紋理與顏色融合到輸入圖中。
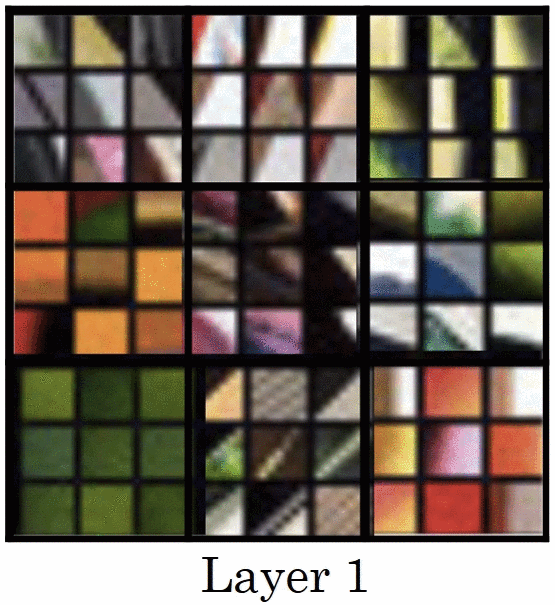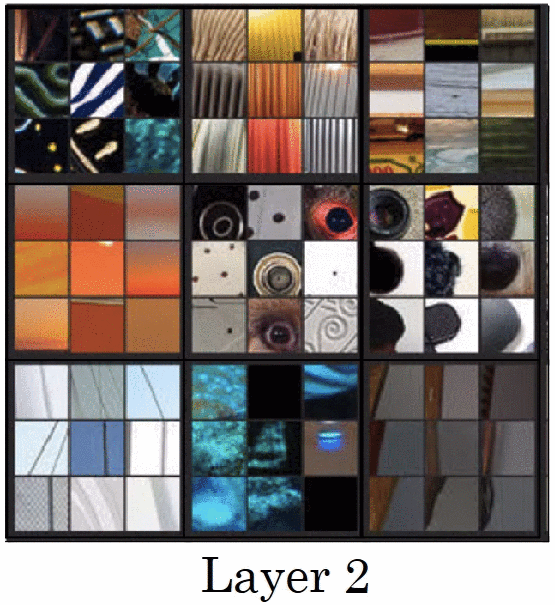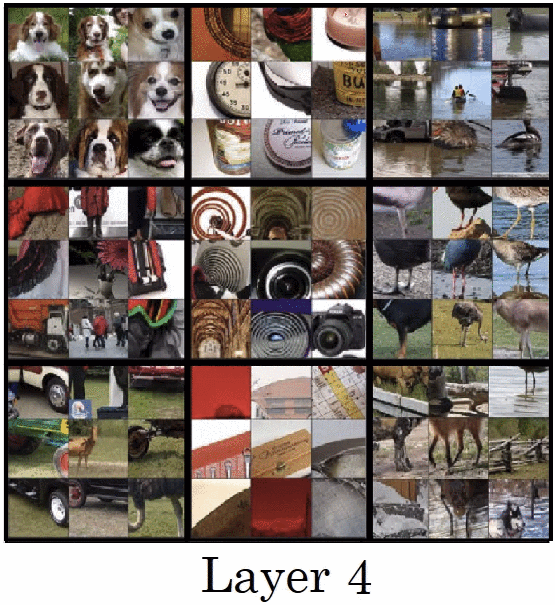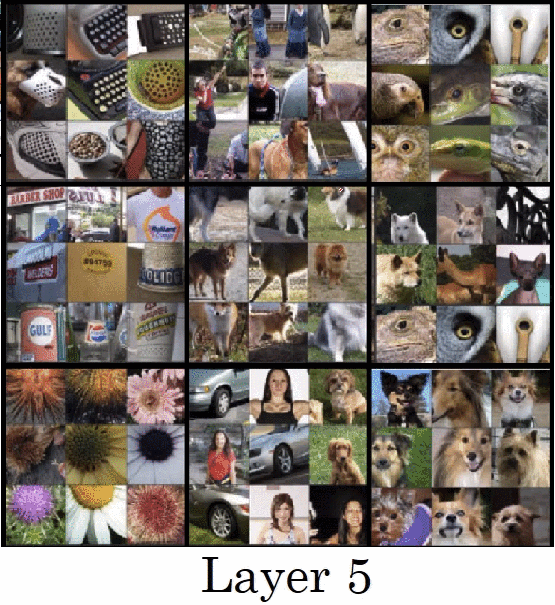
2.1 Methods
原作作法為輸入以下三張圖進一個已經 train 好的 CNN model(原作使用 VGG19,VGG論文 可參考 PyTorch Taipei 2018 第五周由陳峻廷所提供之講解資料 和影片 )中:
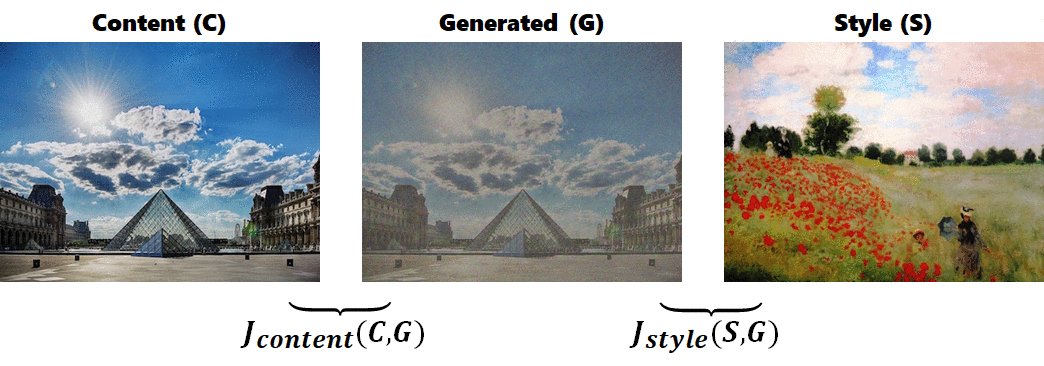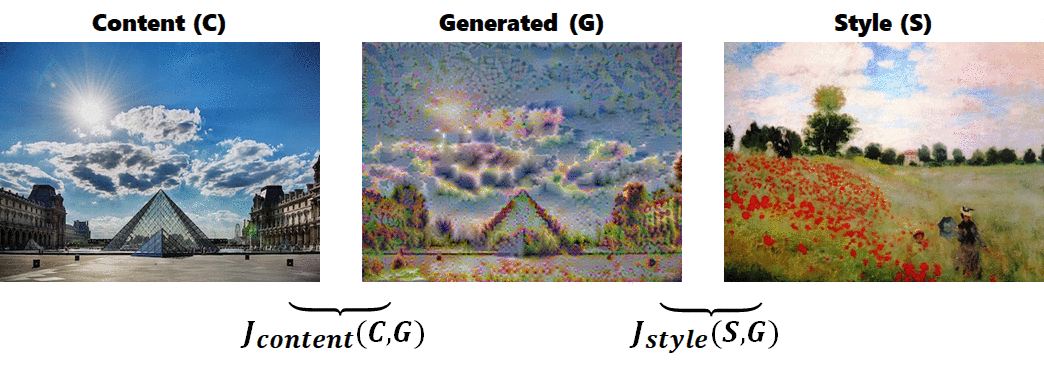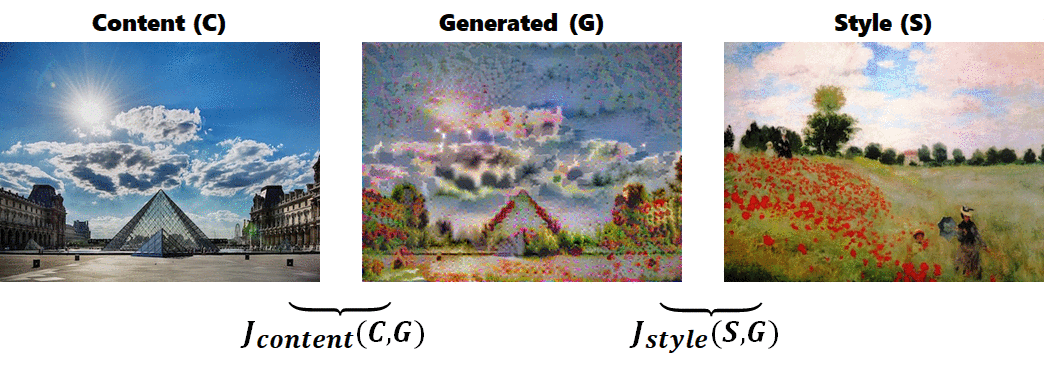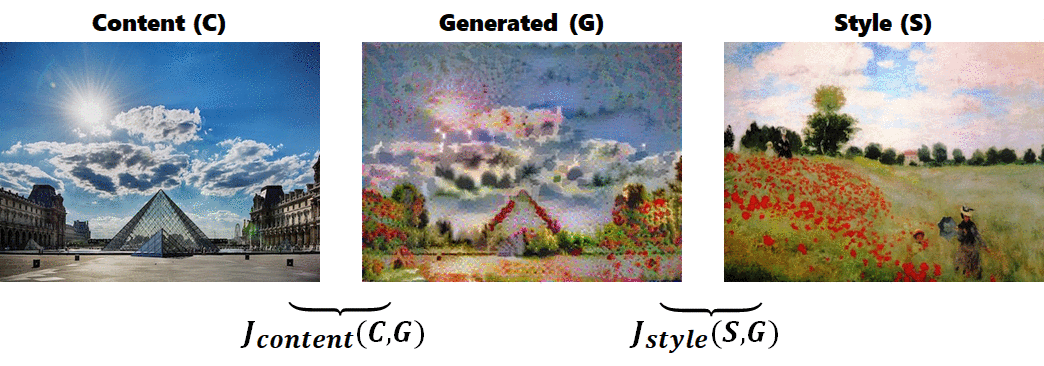
- 內容圖(C): 想要將風格套用於其上的圖片
- 風格圖(S): 含有特殊風格的圖片
- 輸出圖(G): 初始化為和 C 一樣大的 white noise 圖片,或是也可以輸入有雜訊的內容圖
再選擇特定捲積層之 activation 值,分別計算 C, G 之間的 cost function $J_{content}$ 和 S, G 之間的 cost function $J_{style}$,以不同比例相加得到最後的 cost function $J(G)$
$$ J(G) = \alpha J_{content} + \beta J_{style} $$
透過 backprop 迭代更新輸出圖(G)上的 pixel 值以降低$J(G)$,其中$\alpha$和$\beta$的比值可以經調整得到不一樣的輸出效果。
2.2 Content Cost Function
內容圖(C)和輸出圖(G)之間的 cost function 為特定某一捲積層activation 值的函數,這一層通常位在整體架構較中間的位置(原作使用 VGG19 的 conv4_2):
$$ J_{content} = \frac{1}{2} \parallel a^{[l]\left( C \right) } - a^{[l]\left( G \right) } \parallel ^2 $$
其中 $ a^{[l]\left( C \right) }$ 和 $ a^{[l]\left( G \right) }$ 分別為內容圖(C)和輸出圖(G)在第$l$層的 activation 值。如果 $J_{content}$ 小代表內容圖(C)和輸出圖(G)在相同位置上具有相似的特徵。
2.3 Style Cost Function
風格圖(S)和輸出圖(G)之間的 cost function 較為複雜,是一個特定數層捲積層activation 值的函數(原作使用 VGG19 的 conv1_1, conv2_1, conv3_1, conv4_1, conv5_1),目的是要得到 channels 之間的 correlation。
首先要看其中一層的 cost function $J_{style}^{[l]}(S,G)$,實際上為風格圖(S)和輸出圖(G)的Gram matrix 之 normalized mean-sqaured distance。
風格圖(S)和輸出圖(G)在 model 中第$l$層的 Gram matrices $ g^{[l]} $ 大小為 $n_C^{[l]} \times n_C^{[l]}$,矩陣內 entry 值可列式為:
$$ g_{k,k’}^{[l] \left( S \right)} = \sum_{i=1}^{n_H^{[l]}} \sum_{j=1}^{n_W^{[l]}} a_{ijk}^{[l] \left( S \right)} a_{ijk’}^{[l] \left( S \right)} $$
$$ g_{k,k’}^{[l] \left( G \right)} = \sum_{i=1}^{n_H^{[l]}} \sum_{j=1}^{n_W^{[l]}} a_{ijk}^{[l] \left( G \right)} a_{ijk’}^{[l] \left( G \right)} $$
其中 $ a_{ijk}^{[l]} $ 表示該捲積層中位置(height, width, channel)=(i,j,k)的 activation 值。
不過 gram matrix 還是以圖來表示較容易理解:
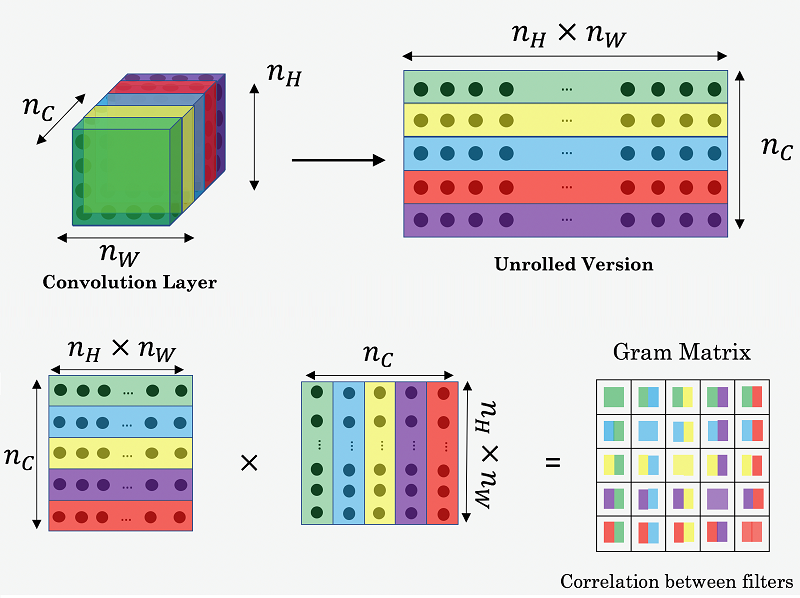
有了 gram matrix 便可得到該層 style cost function:
$$ J_{style}^{[l]}(S,G) = \frac{1}{\left( 2 n_H^{[l]} n_W^{[l]} n_C^{[l]} \right) ^2} \parallel g^{[l] \left( S \right)} - g^{[l] \left( G \right)}\parallel ^2 $$
$$ J_{style}^{[l]}(S,G) = \frac{1}{\left( 2 n_H^{[l]} n_W^{[l]} n_C^{[l]} \right) ^2} \sum_k \sum_{k’} \left( g_{k,k’}^{[l] \left( S \right)} - g_{k,k’}^{[l] \left( G \right)} \right)^2 $$
而每一層的 $ J_{style}^{[l]} $ 再以不同 weighting $ \lambda^{[l]} $ 相加得到 $ J_{style} $ (原作五層 weighting 都是 0.2):
$$ J_{style} = \sum_l \lambda^{[l]} J_{style}^{[l]} $$
2.4 Overall Process
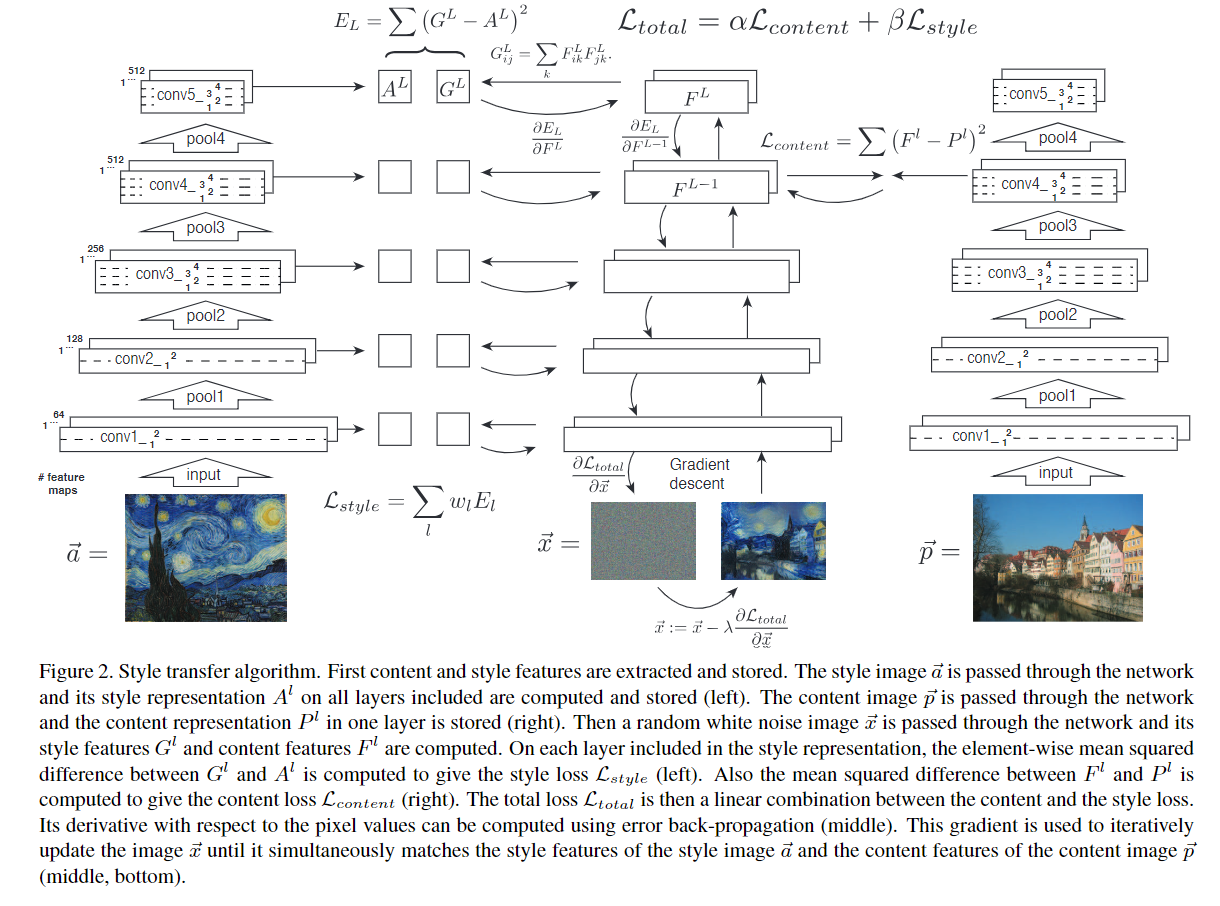
總而言之,$J_{content}$ 只運用 CNN 架構中的某一層的 activation 值,降低$J_{content}$會使輸出圖(G)在內容圖(C)相同位置上出現一樣的特徵,而$J_{style}$ 的計算涵蓋多層的 activation 值,降低$J_{style}$會使輸出圖(G)和風格圖(S)在 CNN 某層上不同 channel 所抓取到的特徵關係相近(不考慮特徵出現位置)。
CVPR 論文內的一張圖(點擊放大)可以概括說明整個流程:
3. Result
論文有展示一些調整參數的效果,我只是撿過來放而已。

圖 8 的 A 為原圖,B~E 為施加不同風格圖的結果,而其所合適之$\alpha / \beta$值也不同: B 為$1 × 10^{−3}$, C 為$8 × 10^{−4}$, D 為$5 × 10^{−3}$, E 和 F 為$5 × 10^{−4}$。


圖 9 左圖: 相同$\alpha / \beta$值與 style cost function,但 content cost function 選取不同層的結果,哪個表現比較好我覺得是見仁見智(?)。
圖 9 右圖:橫軸為不同的 $\alpha / \beta$值,縱軸為 style cost function 涵蓋不同層數,row A 為只計算 conv1_1 一層、row B 為計算 conv1_1 和 conv2_1 兩層、row C 涵蓋三層…依此類推。可見$\alpha / \beta$越小則輸出圖(G)和內容圖(C)相去越遠而只含有風格特徵。而當 style cost function 只計算 conv1_1 一層則表現出較細微的風格特徵,計算涵蓋越深層則有較大的風格特徵。
4. Discussion
本篇論文演算法較為簡單,然而實際運行結果有一些比較明顯的缺失:
- 未考慮空間、亮度等因素: 例如可能會把地面的特徵套用在天空之類的情況。不過第一作者後續有出了數篇針對改善這個缺點的論文,像是這篇 和這篇 。
- 又肥又慢: VGG 在 CNN 發展歷史中曾獲得一時的勝利是因為增加了很多層的捲積層,造成 model 很佔空間、執行時間也比較久。不過在本文開頭就告訴大家已經有 real-time 的產品,代表已經有多篇關於能夠快速執行 style transfer 的論文被發表了。
目前已經有 style transfer 領域的review paper 了,有興趣可以去看看學界後來又延伸發展了那些主題或改善方法。
Reference
- 本篇文章介紹之 style transfer 論文
- 在 arXiv 上發布的論文: Gatys, L.A., Ecker, A.S., Bethge, M.: A neural algorithm of artistic style. arXiv preprint arXiv:1508.06576 (2015)
- 在 CVPR 上發表的論文: L. A. Gatys, A. S. Ecker and M. Bethge, “Image Style Transfer Using Convolutional Neural Networks,” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, 2016, pp. 2414-2423. doi: 10.1109/CVPR.2016.265
- PyTorch Code @ GitHub
- ZFNet
- VGG
- 吳恩達在 Coursera 上開設之深度學習線上課程
- PyTorch official tutorial
- Mark Chang’s slides & video (偏重實驗的講解,很值得一看)
- 講解影片
- Neural Style Transfer: A Review